在R教学中,首先要跨过去的一座大山就是乱码问题。很多学生在装好R和RStudio之后,刚刚运行RStudio,还未尝个鲜,写出R的第一段甚至人生第一段hello world代码,乱码就来立个下马威了(此处应该有乱码翻车现场截图,但对系统干净清爽的博主来说要制作这么一张图还是有难度的,哪位读者愿意贡献一张?)。
对于许多从 Stata 转过来的社科领域研究人员来说,在学习和使用R的过程中是如此频繁地遭遇乱码问题更是一件很不可思议的事情。乱码无处不在,令人抓狂,令人崩溃,茶饭不思,错过DDL,成为一块死肉。的确,相对于封闭的Stata来说,作为开放系统的R不仅要处理作为数据的文本,还需同各种系统进行数据交换,结果输出到各类格式中,必须要支持各种字符编码。然而文本编码作为计算机领域的专门知识,不仅普通使用者不懂,大多数R包的开发者也不甚了解,代码可能写的不规范,再加上 R 语言与 c 语言的交互调用,于是就出现了异常复杂的R生态乱码问题。不仅导入数据时乱码,输出结果时乱码,制图时乱码,甚至原本正确的编码到了中间某一步就乱码了。
博主作为资深文科生,今天却要自不量力地对R的乱码问题做一些解析,提供一些解决思路,以飨后来者。
先让RStudio运行起来
对于那些第一次运行RStudio就遭遇车祸的童鞋来说,大部分都是 Windows 用户,而且 Windows 的账户用的是中文名。
在此,先强调两个傻瓜原则,能给将来避免很多麻烦:
R以及RStudio的安装路径不要有中文和空格,必须全英文。- Windows 账户要用英文!
那么已经设置了中文帐户名的怎么办?
- 一劳永逸的办法,当然是新建一个英文账户登录了;
- 若是不会上面的操作,或者觉得切换账户太麻烦,可以改一下 Windows 的临时目录:
右键“我的电脑”-“属性”-“高级系统设置”-“环境变量”,将 temp 和 tmp 都设为 c:\windows\temp\(下图红框所示):
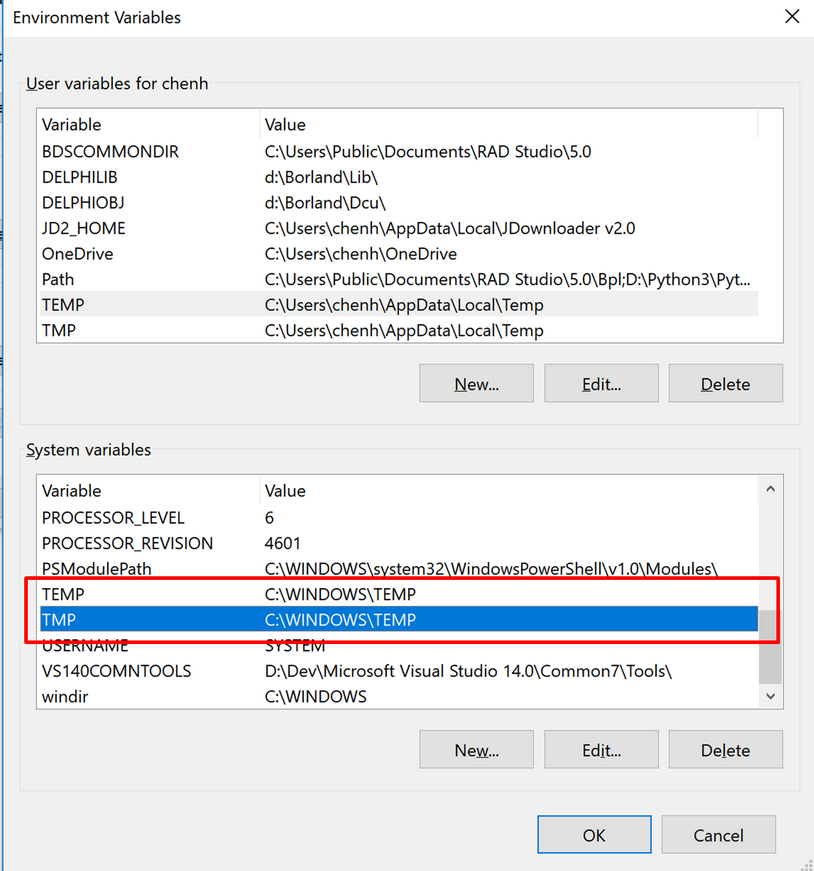
一路确定之后,重启 RStudio 就可以去敲写人生第一行R代码了。
那么,在 MacOS 下翻车的用户怎么办?博主不用 Mac,所以现在没法复原车祸现场,请快递一台 MacBook Pro 以便博主更好地服务大众。
R 的字符编码
在介绍R的字符编码之前,还是得有一些关于文本编码的基本知识,建议先读读这篇,包括下面的评论。
这个世界上的文本编码方案千百种,有些 linux 的支持者及R包开发者号称要用 UTF-8 一统天下,可惜这只能是一厢情愿,因为很多字符超出了 UTF-8所能涵盖的范围。不得不承认,大多数R包开发者用的是 linux 或 Mac 系统,得益于以 UTF-8 作为整个体系的基础,避免了很多乱码的情形。但也正是他们写的不规范,才导致了 Windows 下罄竹难书的灾难性后果啊。字符编码不仅有方案之争,还有系统之争,关于 BOM 的吵架就有一罗锅。作为实用主义者的文科僧,博主只关心如何保证文本编码的正确传递、显示和输出。
先提供两个基本的函数:
1、纠正乱码的一招鲜
碰到乱码,一般可以先尝试一下,给它设置一个正确的编码:
Encoding(someX)<-'UTF-8'
# 或者
Encoding(someX)<-'GB2312'
前一句告诉R,这是个 UTF-8编码的字符,后一句则是告诉 R 这是简体中文国标码编码的字符,你给我按照这个方式打印出来!如果这一招能搞定,则万事大吉,继续码农之旅吧。否则,则真正的麻烦开始了。
由此可见,R 之所以能正确处理字符编码,靠的是给不同编码方案的字符提供一个标记,例如上面代码中的 UTF-8 以及 GB2312。若是这个标记设置错误,不仅显示乱码,后续的字符查找、匹配、替换等操作也会跟着出问题。例如下面这段代码强行将 x 的编码设为国标码,就造成了显示输出的乱码。
Encoding(x)
## [1] "UTF-8"
Encoding(x) <- 'GB2312'
x
## [1] "涓枃"
当然,对于这种编码设置错误的情形,不必过于担心,在对字符进行任何__改动__操作之前都是安全的,只需将正确的编码标记告诉 R 即可。
2、编码转换引擎
已知一个字符对象的编码,需要将它转换为别的编码,用 iconv() 实现:
x <- '中文'
Encoding(x)
## [1] "unknown"
x2 <- iconv(x, 'GB2312', 'UTF-8')
Encoding(x2)
## [1] "UTF-8"
iconv() 有两个比较重要的参数:from 指原始的编码方案,to 指目标编码方案。iconv() 也不管 x 原来是什么编码,只会按照 from 的指示行事。
3、如何判断字符的正确编码?
那么,若是导入数据时遇到乱码,除了用不同的编码值去猜测之外,有没有什么办法去自动识别字符的编码呢?从编码规则上来说似乎并没有非常确切的识别方法(结合编码规则以及文本规律,可以考虑tellenc),除了那些带有 BOM 标识的 Unicode 文本。根据文件头的 BOM 标识,可以自动识别文本是 UTF-8 还是 UTF-16,是大头(big endian)还是小头(little endian)。听上去很完美对不对?可惜 linux 的拥趸不这么干。于是,我们要面对这个混杂的世界。
更重要的的是,R 对编码具有很好的包容能力,尽管目前力有不逮但仍努力在背后去自动应对不同的编码,甚至混合编码。在第二篇,再来解决混合字符编码的问题。我们首先要知道,在同一个 R 字符对象中,是可以有不同编码方案的。
x <- '中文'
x[2] <- iconv('中文', to = 'UTF-8')
x
## [1] "中文" "中文"
Encoding(x)
## [1] "unknown" "UTF-8"
那么最坏的情况就是我们需要导入一个外部数据文本,可能是国标码,也可能是UTF-8编码,甚至是混合的。万幸的是我们可以对 UTF-8 做一个小小的自动判定(大约99%的情况下是对的)。来看看一个文本导入的示例。为了这个示例,博主特意准备了一个比较乱的原始数据,既包含国标码的中文也包括 UTF-8 编码的中文。同时,再随机地设置其中一些为 UTF-8。这样,测试数据中无论是国标码的文本还是 UTF-8 编码的文本同时都有编码声明正确和错误的两种情形。
xx <- readLines("e:/Huashan/Stat/R/Demo/encoding/data/mixed.txt")
xx
## [1] "这是一段中文gb码" "杩欐槸涓€娈典腑鏂噓tf8鐮\x81"
# 复制10遍再乱序
xx <- rep(xx, times=10)
Encoding(xx)[sample(length(xx))] <- 'UTF-8'
xx <- xx[sample(length(xx))]
Encoding(xx) <- 'GB2312'
Encoding(xx)[huashan::isUTF8(xx)] <- 'UTF-8'
xx
## [1] "这是一段中文gb码" "这是一段中文gb码" "这是一段中文gb码"
## [4] "这是一段中文utf8码" "这是一段中文gb码" "这是一段中文utf8码"
## [7] "这是一段中文utf8码" "这是一段中文gb码" "这是一段中文utf8码"
## [10] "这是一段中文utf8码" "这是一段中文gb码" "这是一段中文gb码"
## [13] "这是一段中文gb码" "这是一段中文gb码" "这是一段中文utf8码"
## [16] "这是一段中文utf8码" "这是一段中文gb码" "这是一段中文utf8码"
## [19] "这是一段中文utf8码" "这是一段中文utf8码"
对了,秘诀就是 huashan 包中的 isUTF8() 函数。
4、默认字符编码
让我们再看这段最简单的示例:
x <- '中文'
Encoding(x)
## [1] "unknown"
上述命令的结果可能各有不同,一般情况下,Windows 用户得到 unknown 而 Mac 用户得到 UTF-8。如果 Mac 用户得到的结果不是 UTF-8,那么恭喜你,你可能会有麻烦了。
上述代码传达了两个信息:
- 同样的代码,在不同的系统中跑,可能是两个结果。对于不喜欢不确定性的程序员来说,这是一件可怕的事情。类似的情形在上机课或者交作业中也经常见到,往往是同学B找同学A要解决方案,结果发现在自己的机上跑不过,连抄个代码都忒么这么为难我!
- 万幸的是,
R的默认字符编码取决于某种系统设置。
这第二点在于操作系统的区域设置,和 Sys.getlocale()、Sys.setlocale() 这两个函数有关。
Sys.getlocale()
## [1] "LC_COLLATE=Chinese (Simplified)_China.936;LC_CTYPE=Chinese (Simplified)_China.936;LC_MONETARY=Chinese (Simplified)_China.936;LC_NUMERIC=C;LC_TIME=Chinese (Simplified)_China.936"
x <- '中文'
Encoding(x)
## [1] "unknown"
Sys.setlocale('LC_CTYPE', locale = "English_United States.1252")
## [1] "English_United States.1252"
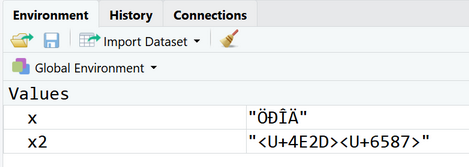
x2 <- '中文'
Encoding(x2)
## [1] "UTF-8"
尽管通过更改区域设置实现了创建一个默认字符编码为 UTF-8的字符对象x2,输出也没有问题,但是作为本地编码的 x 却不能正常显示了。由此可见,在默认 UTF-8 编码的系统下,只能正确显示 UTF-8 一种编码,其它编码都不能正常显示,必须通通转成 UTF-8 才行。Mac 系统就是如此。但在 Windows 下作为国标编码的中文和作为 UTF-8 编码的中文均能同时正常显示。这是一种优点,也是缺点,后续将有例子展示。

另外,在RStudio中,x2 的显示也不那么让人舒心,如下图。除非将 Sys.setlocale() 设在 RStudio 启动之前。所以在 Windows 下,一般不建议更改系统的 locale。