这两年来 markdown 越发流行于各类网络客户端系统,各大博客系统、wiki系统、团队协作系统都纷纷支持 markdown 语法,支持 markdown 的编辑器也越来越多。但真正将 markdown 用于学术论文或出版物写作的实践却并不多。在此介绍一下本人自2012年来就开始打造的一套工作流程。
先介绍流程的两大基石:
knitr 背后的功臣——pandoc
markdown 起源于email写作中的简单格式,其语法非常简单,可能对 markdown 略有耳闻的人会觉得它不过是个玩具。其实不然,markdown 本身并非一个统一的语法,事实上有很多版本的实现。比较有经验的R用户可能经常用 knitr 来做一些数据报告,甚至用 knitr book 来写数据类长篇大作,或许你们还不知道,knitr 背后有个默默无名的英雄—— pandoc。这是一款由一名伯克利大学哲学系教授领衔开发的 markdown 超级语法及文档格式转换工具。与普通网页版的简易 markdown 语法不同,pandoc 可以说是学术 markdown,除了常规的 markdown 元素以外,它还支持学术论文中常见的公式、表格、参考文献、脚注、尾注的格式化输出。 不仅如此,它还是一款超级格式机,能与大量的文档格式进行转换,它支持的格式是如此之多我就不贴大图了,仅手绘一张 pandoc 流程图做一示意:
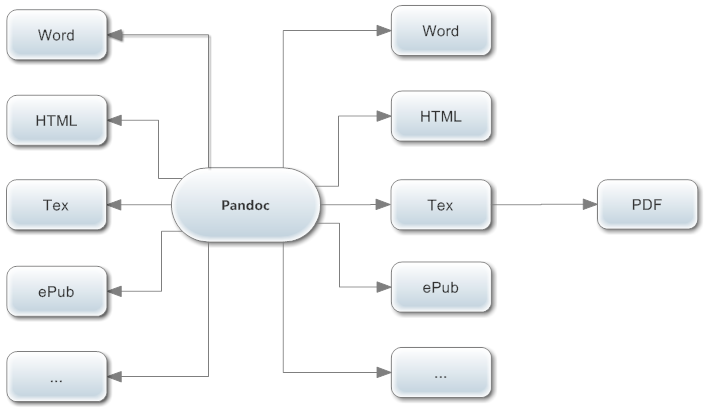
所以,有了 pandoc 这个超级工具,社科量化小白用户再也无需羡慕理工科学生手里能输出漂亮公式的 latex 了,用 markdown 同样能输出漂亮公式,beamer 幻灯片也不在话下,再也不用啃三个月 latex 手册了。而且,印刷论文的时候可以用漂亮的pdf输出,要求论文电子版存档就交个 word 交差,何其方便!
思维脑图写作——mindmanager
前面说了简单数据报告可以采用 knitr ,但完整的社科类论文写作还是很难完全依赖它的。除了社科类论文中,数据分析在文章中占比不大以外,更重要的是思维差异。写作思维与编程思维是完全不同的!数据分析过程,强调数据结构和处理逻辑的一致性,强调代码的重用性,尽量避免重复代码,而对计算结果进行分析和写作则是基于分类和演绎的逻辑来进行,很多时候,我们需要用多种口径检查计算结果,但并不会将其都放在论文中。个人经验,最有效的方式还是把这二者分开,各行其是才好。
脑图类软件无疑是整理构思、研究素材、论文结构的极好工具。脑图类软件也有很多,收费的、开源的、在线的,那么是不是随便搞个看着顺眼的就可以了?当然不是了。整理构思、管理素材固然是用脑图软件的一大目的,但是还得将它与 makrdown 文字相结合起来。该软件比如符合两个要求:
- 能够添加笔记:这条就杀掉了大多数在线脑图;
- 提供二次开发 API:添加笔记的目的是用来书写内容,而 API 则是为这些笔记的输出提供各种可能性。
所以我选择了 mindmanager:丰富的 OLE 接口,可以用来任意自定义脑图结构和笔记的输出方式。例如如何划分章、节和小节,第四级以下的脑图节点是否还作为小小节;不同输出版本的生成,例如下图中,标记有 advanced 的单独输出为一个版本。
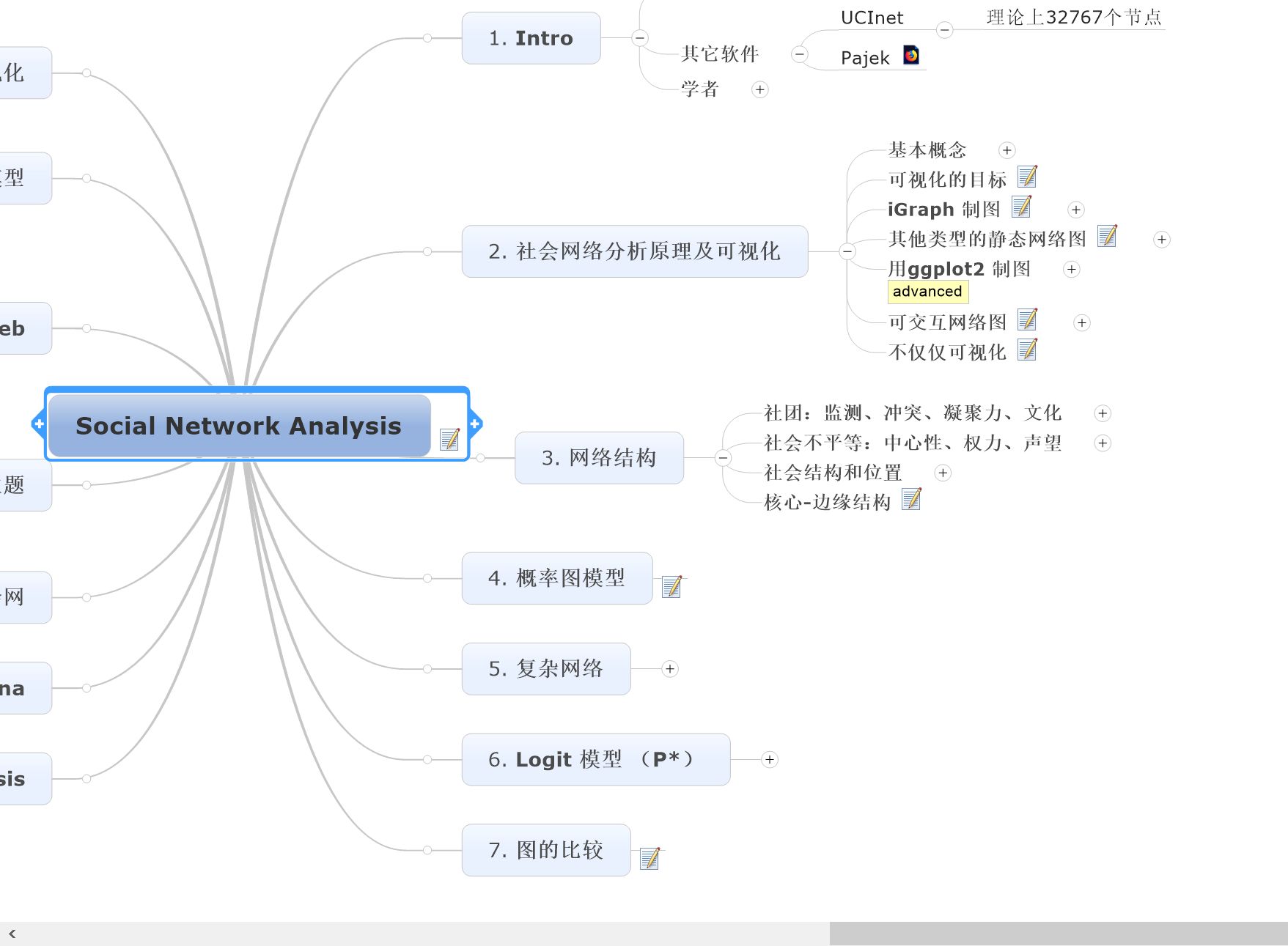
有 API 的好处是,还可以对笔记内容在变成 markdown 正文前进行处理。例如可以将笔记中的图片直接转为 [img](path_to_image) 这样的语法,充分利用笔记本身所见即所得的功能。例如分枝标题上的 - 表示不显示该小节标题:

更进一步,在笔记内部进行再分页、分章节也完全不是问题。同一个脑图,即可以输出为文章,也可以输出为幻灯片,一切取决于你的相像!最后,mindmanager 的 OLE 接口语法是如此简单,只需要简单的 visual basic 知识就足以搞定。
流程整合:Paper Composer
有了上面两大基石的加持,只需小小地在 mindmanager OLE 接口上下点功夫,论文编译器就出台了!
主界面来了,嗒哒!
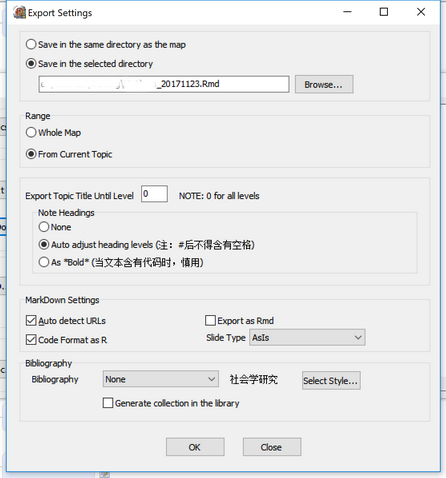
功能也不多,随想随加:
- 输出的
markdown文件存放路径; - 导出脑图范围:全部 vs. 分枝;
- 章节层级;
- 是否作为
Rmd输出,以供knitr运算; - 参考文献格式化;
- 根据 tag 标识选择不同分枝输出;
- 最终格式选择:Word, HTML, pdf;
还剩了一些问题,例如:
- 参考文献格式化;
- R 的输出如何整合;
- 导出到 Word 时的问题:模板设置、表格图片自动编号;表格边框设置;
请持续关注。