目的
- 在导入 SPSS Stata 等格式时,提供统一的处理标签的接口;
- 在输出表格时提供对标签的自动化处理;
什么是标签
SPSS 和 Stata 的用户最熟悉标签:
- 变量标签
gender `性别`
age `年龄`
- 数值标签
gender:
1 = 男性
2 = 女性
R 中如何处理标签
首先,data.frame 没有变量标签的概念(attr 另外再说),变量名行使标签的功能:
table(dt$`性别`)
# 如果标签有空格
table(dt$`a variable`)
其次,可用 factor 提供数值标签功能(factor 其实就等价于字符型):
levels(df$`性别`) <- c('男', '女')
R 包对标签的处理
通过对象属性设置来保存标签:
foreign
attr(df, 'variable.labels') # 变量标签
attr(var, 'value.labels') # 数值标签
haven
和 foreign 道理一样,只不过命名方式不同。此外,haven 把变量标签和数值标签都作为变量的属性,而在 foreign 中,变量标签是 data.frame 的属性,数值标签才是变量的属性。
attr(var, 'label')
attr(var, 'labels')
显示在 RStudio 中是这样的:
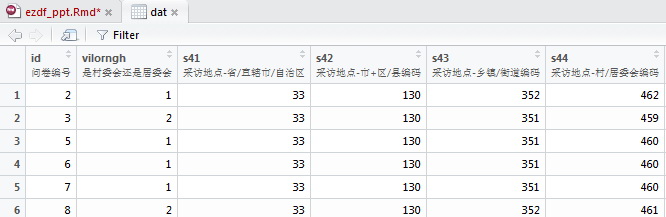
ezdf 提供统一的数据导入接口
- 对数据导入提供统一接口,封装
foreign、haven等包的导入函数; - 修正一些 bug,例如:
`haven`: “Error: `x` and `labels` must be same type”
导入 Stata 数据
导入 Stata 数据使用 readStata() 函数:
library(ezdf)
dat <- readStata('CGSS2013(居民问卷)发布版_2014.dta', encoding = 'GB2312')
# View(dat)
# 参数 `encoding` 设置 Stata 标签的编码,该参数默认值为 UTF-8。
# 有的 Stata 数据对变量名以及字符变量(string)的值都采用不同编码,对于这种情况,
# 需分别设置 `varNameEncoding` 和 `charEncoding`。
dat <- readStata('CGSS2013(居民问卷)发布版_2014.dta', encoding = 'GB2312',
varNameEncoding = 'UTF-8', charEncodin = 'UTF-8')
导入 SPSS 数据
导入 SPSS 数据使用 readSPSS() 函数
# 参数 `lib` 设置导入所使用的 R 包,目前支持 `foreign` 和 `haven`。
readSPSS(file, lib = "foreign", ...)
将 data.frame 转换为 ezdf
用 as.ez(dt, meta) 创建一个新的 ez.data.frame 对象
data(iris)
library(ezdf)
d1 = as.ez(iris)
class(d1)
## [1] "ez.data.frame" "data.table" "data.frame"
ezdf 对标签的设置
变量标签
- 变量标签存储在
meta属性当中; meta可为data.frame或matrix类型对象:至少包括两列:第一列为变量名,第二列为变量标签。
两个辅助函数:
- `setmeta()`
- `getmeta()`
d1$test = sample(5, size = nrow(iris), replace = T)
# 对新变量 test 设置变量标签
setmeta(d1, data.frame(var= 'test', lbl = '这是新变量标签'))
# 显示数据 d1 的全部变量标签
attr(d1, 'meta')
## var lbl
## 1: test 这是新变量标签
# 或者
getmeta(d1)
## var lbl
## 1: test 这是新变量标签
varLabels(d1, c('Species', 'test'))
## [1] "" "这是新变量标签"
# 用 default = "var" 只输出带有标签的变量
varLabels(d1, c('Species', 'test'), default = "var")
## [1] "Species" "这是新变量标签"
# 返回所有已定义的变量标签
varLabels(d1)
## var lbl
## 1: test 这是新变量标签
单独设置部分变量标签
# 设置变量标签
varLabels(d1, "test") <- "新标签"
varLabels(d1, "test")
## [1] "新标签"
数值标签
数值标签的存储采用命名整数向量作为变量的 labels 属性
# 定义一个数值标签
c(C1 = 1, C2 = 2, C3 = 3, MI = 9)
valueLabels()
vl1 = valueLabels(d1, 'test')
vl1
## list()
## attr(,"class")
## [1] "value.labels"
## attr(,"ez")
## [1] "d1"
## attr(,"col")
## [1] "test"
# 数值标签可以“加减”。
# 注意: MI=9 设了一个不存在的值标签
vl2 = vl1 + c("Class1"=1, "Class2"=2, "Class3"=3, 'Class4'=4, 'Class5' = 5, MI = 9, MM = 8)
valueLabels(d1, 'test') = vl2
制表函数
tbl()
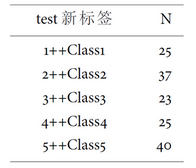
tbl(d1, ~test)
## test\t新标签 N
## 1: 1++Class1 25
## 2: 2++Class2 37
## 3: 3++Class3 23
## 4: 4++Class4 25
## 5: 5++Class5 40
# 分组求均值,添加样本数
tbl(d1, Sepal.Length ~ Species + test, 'mean', N = T)
## Species test\t新标签 Sepal.Length N
## 1: setosa 1++Class1 5.141667 12
## 2: setosa 2++Class2 4.923077 13
## 3: setosa 3++Class3 5.200000 5
## 4: setosa 4++Class4 5.044444 9
## 5: setosa 5++Class5 4.836364 11
## 6: versicolor 1++Class1 5.900000 4
## 7: versicolor 2++Class2 5.941667 12
## 8: versicolor 3++Class3 5.908333 12
## 9: versicolor 4++Class4 6.142857 7
## 10: versicolor 5++Class5 5.866667 15
## 11: virginica 1++Class1 6.533333 9
## 12: virginica 2++Class2 6.583333 12
## 13: virginica 3++Class3 6.883333 6
## 14: virginica 4++Class4 6.344444 9
## 15: virginica 5++Class5 6.657143 14
# tbl() 默认按照公式右端 x 的值排序,如果取消排序
tbl(d1, Sepal.Length ~ Species + test, 'mean', N = T, sort = F)
## Species test\t新标签 Sepal.Length N
## 1: setosa 4++Class4 5.044444 9
## 2: setosa 5++Class5 4.836364 11
## 3: setosa 1++Class1 5.141667 12
## 4: setosa 2++Class2 4.923077 13
## 5: setosa 3++Class3 5.200000 5
## 6: versicolor 4++Class4 6.142857 7
## 7: versicolor 2++Class2 5.941667 12
## 8: versicolor 5++Class5 5.866667 15
## 9: versicolor 3++Class3 5.908333 12
## 10: versicolor 1++Class1 5.900000 4
## 11: virginica 4++Class4 6.344444 9
## 12: virginica 5++Class5 6.657143 14
## 13: virginica 2++Class2 6.583333 12
## 14: virginica 1++Class1 6.533333 9
## 15: virginica 3++Class3 6.883333 6
ctbl()
ctbl() 是对 table() 的封装,采用 ctbl(ez, expr) 的调用方式。
ctbl(d1, Sepal.Length ~ Species + test)
# 等价于
table(d1$Sepal.Length, d1$Species, d1$test)
ftable()
ftable.ez.data.frame() 方法是对 ftable() 的封装
ftable(ez, formula, style = 1, prop_margin = 1, ...)
prop_margin: 行百分比 / 列百分比;style = 1:输出频次;style = 2:输出百分比;style = 3:输出百分比和行加总频次。
ftable(d1, Species~test)
##
## setosa versicolor virginica
## 1++Class1 12 4 9
## 2++Class2 13 12 12
## 3++Class3 5 12 6
## 4++Class4 9 7 9
## 5++Class5 11 15 14
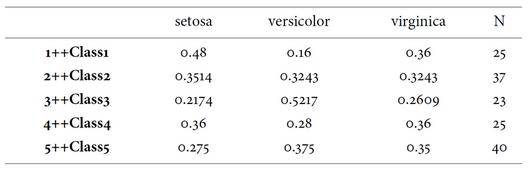
ftable(d1, Species~test, style = 2)
##
## setosa versicolor virginica
## 1++Class1 0.4800000 0.1600000 0.3600000
## 2++Class2 0.3513514 0.3243243 0.3243243
## 3++Class3 0.2173913 0.5217391 0.2608696
## 4++Class4 0.3600000 0.2800000 0.3600000
## 5++Class5 0.2750000 0.3750000 0.3500000
(t1 = ftable(d1, Species~test, style = 3))
## setosa versicolor virginica N
## 1++Class1 0.4800000 0.1600000 0.3600000 25
## 2++Class2 0.3513514 0.3243243 0.3243243 37
## 3++Class3 0.2173913 0.5217391 0.2608696 23
## 4++Class4 0.3600000 0.2800000 0.3600000 25
## 5++Class5 0.2750000 0.3750000 0.3500000 40
与 markdown 流程整合
pander是用于 markdown 格式输出的 R 包,提供了非常丰富的表格输出功能- 在加载
ezdf包之后,会自动与pander包结合,实现自动标签输出
# pander 输出
library(pander)
pander(t1, ez = d1)
这是输出的 markdown 结果:
-----------------------------------------------------
setosa versicolor virginica N
--------------- -------- ------------ ----------- ---
**1++Class1** 0.48 0.16 0.36 25
**2++Class2** 0.3514 0.3243 0.3243 37
**3++Class3** 0.2174 0.5217 0.2609 23
**4++Class4** 0.36 0.28 0.36 25
**5++Class5** 0.275 0.375 0.35 40
-----------------------------------------------------
最终输出效果:
pander 与回归结果输出:
# 加上数值标签
options('ezdfKeepVal' = T)
pander(tbl(dat, a66 ~ s5a, 'mean'))
---------------------------------------------------------
s5a 受访者居住的地区类型是 a66 您家是否拥有家用小汽车
---------------------------- ----------------------------
1++市/县城的中心地区 1.761
2++市/县城的边缘地区 1.775
3++市/县城的城乡结合部 1.809
4++市/县城区以外的镇 1.859
5++农村 1.919
---------------------------------------------------------

数值与标签之间分隔符
options('ezdfValueLabelSep' = '=')
pander(tbl(dat, a66 ~ s5a, 'mean'))
---------------------------------------------------------
s5a 受访者居住的地区类型是 a66 您家是否拥有家用小汽车
---------------------------- ----------------------------
1=市/县城的中心地区 1.761
2=市/县城的边缘地区 1.775
3=市/县城的城乡结合部 1.809
4=市/县城区以外的镇 1.859
5=农村 1.919
---------------------------------------------------------

回归模型的输出:
m1 = lm(a6 ~ a2 + a10, dat)
pander(m1)
这是通过 markdown 输出转成 pdf 后的效果,没有任何手工干预(pandoc 在输出小数点时,还有一点瑕疵,比如小数点位数不统一,不过本人 github 上的版本已经修正了这个问题)。
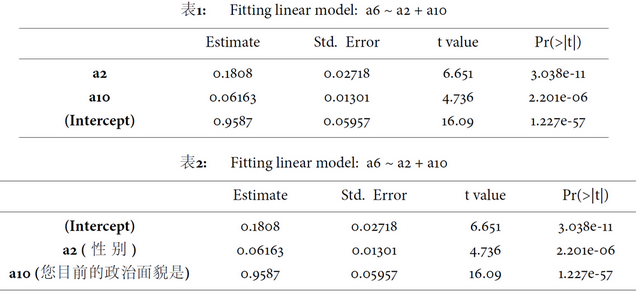
表格输出选项
目前提供三个选项:
options('ezdfKeepVal' = T)options('ezdfValueLabelSep' = '=')options('ezdfKeepVarName' = T)
options('ezdfKeepVal' = T)
options('ezdfValueLabelSep' = '=')
options('ezdfKeepVarName' = F)
tbl(d1, ~test)
## 新标签 N
## 1: 1=Class1 25
## 2: 2=Class2 37
## 3: 3=Class3 23
## 4: 4=Class4 25
## 5: 5=Class5 40
pander(tbl(d1, ~test))
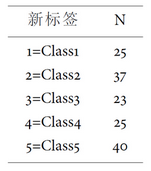
options('ezdfKeepVarName' = T)
options('ezdfValueLabelSep' = '++')
pander(tbl(d1, ~test))
下载与安装
github: https://github.com/huashan/ezdf
devtools::install_github('huashan/pander')